Question # 1
You need to recommend a Fabric streaming solution that will use the sources shown in the
following table.
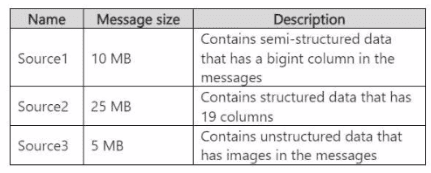
The solution must minimize development effort.
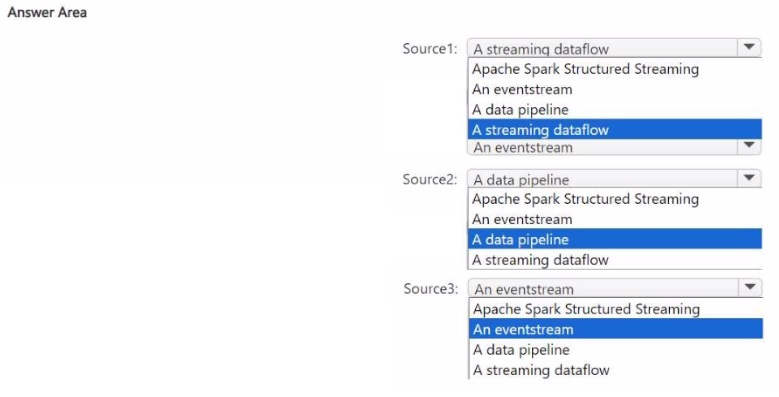
What should you include in the recommendation for each source? To answer, select the
appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
 |
Question # 2
You have a Fabric warehouse named DW1 that contains four staging tables named
ProductCategory, ProductSubcategory, Product, and SalesOrder. ProductCategory,
ProductSubcategory, and Product are used often in analytical queries.
You need to implement a star schema for DW1. The solution must minimize development
effort.
Which design approach should you use? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
 |

Question # 3
Note: This question is part of a series of questions that present the same scenario. Each
question in the series contains a unique solution that might meet the stated goals. Some
question sets might have more than one correct solution, while others might not have a
correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result,
these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL
database. The table contains the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at
least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:

Does this meet the goal? | | A. Yes | | B. no |
B. no
Explanation:
This code does not meet the goal because it uses sort by without specifying the order,
which defaults to ascending, but explicitly mentioning asc improves clarity.
Question # 4
You have a Fabric workspace named Workspace1 that contains a lakehouse named
Lakehouse1. Lakehouse1 contains the following tables:
Orders
Customer
Employee
The Employee table contains Personally Identifiable Information (PII).
A data engineer is building a workflow that requires writing data to the Customer table,
however, the user does NOT have the elevated permissions required to view the contents
of the Employee table.
You need to ensure that the data engineer can write data to the Customer table without
reading data from the Employee table.
Which three actions should you perform? Each correct answer presents part of the
solution.
NOTE: Each correct selection is worth one point. | | A. Share Lakehouse1 with the data engineer. | | B. Assign the data engineer the Contributor role for Workspace2. | | C. Assign the data engineer the Viewer role for Workspace2. | | D. Assign the data engineer the Contributor role for Workspace1. | | E. Migrate the Employee table from Lakehouse1 to Lakehouse2. |
A. Share Lakehouse1 with the data engineer.
D. Assign the data engineer the Contributor role for Workspace1.
E. Migrate the Employee table from Lakehouse1 to Lakehouse2.
Explanation:
To meet the requirements of ensuring that the data engineer can write data to the
Customer table without reading data from the Employee table (which contains Personally
Identifiable Information, or PII), you can implement the following steps:
Share Lakehouse1 with the data engineer.
By sharing Lakehouse1 with the data engineer, you provide the necessary access to the
data within the lakehouse. However, this access should be controlled through roles and
permissions, which will allow writing to the Customer table but prevent reading from the
Employee table.
Assign the data engineer the Contributor role for Workspace1.
Assigning the Contributor role for Workspace1 grants the data engineer the ability to
perform actions such as writing to tables (e.g., the Customer table) within the workspace.
This role typically allows users to modify and manage data without necessarily granting
them access to view all data (e.g., PII data in the Employee table).
Migrate the Employee table from Lakehouse1 to Lakehouse2.
To prevent the data engineer from accessing the Employee table (which contains PII), you
can migrate the Employee table to a separate lakehouse (Lakehouse2) or workspace (Workspace2). This separation of sensitive data ensures that the data engineer's access is
restricted to the Customer table in Lakehouse1, while the Employee table can be managed
separately and protected under different access controls.
Question # 5
You have a Fabric workspace named Workspace1 that contains a notebook named
Notebook1.
In Workspace1, you create a new notebook named Notebook2.
You need to ensure that you can attach Notebook2 to the same Apache Spark session as
Notebook1.
What should you do? | | A. Enable high concurrency for notebooks. | | B. Enable dynamic allocation for the Spark pool. | | C. Change the runtime version. | | D. Increase the number of executors. |
A. Enable high concurrency for notebooks.
Explanation:
To ensure that Notebook2 can attach to the same Apache Spark session as Notebook1,
you need to enable high concurrency for notebooks. High concurrency allows multiple
notebooks to share a Spark session, enabling them to run within the same Spark context
and thus share resources like cached data, session state, and compute capabilities. This is
particularly useful when you need notebooks to run in sequence or together while
leveraging shared resources.
Question # 6
You have a Fabric workspace named Workspace1 that contains a warehouse named
Warehouse1.
You plan to deploy Warehouse1 to a new workspace named Workspace2.
As part of the deployment process, you need to verify whether Warehouse1 contains
invalid references. The solution must minimize development effort.
What should you use? | | A. a database project | | B. a deployment pipeline | | C. a Python script | | D. a T-SQL script |
C. a Python script
Explanation:
A deployment pipeline in Fabric allows you to deploy assets like warehouses, datasets, and
reports between different workspaces (such as from Workspace1 to Workspace2). One of the key features of a deployment pipeline is the ability to check for invalid references before
deployment. This can help identify issues with assets, such as broken links or
dependencies, ensuring the deployment is successful without introducing errors. This is the
most efficient way to verify references and manage the deployment with minimal
development effort.
Question # 7
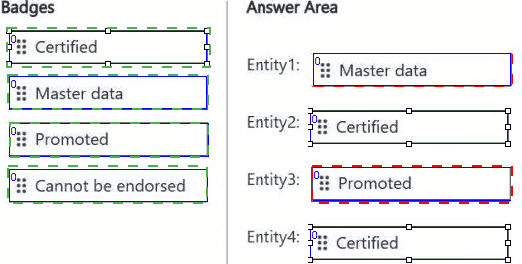
You are implementing the following data entities in a Fabric environment:
Entity1: Available in a lakehouse and contains data that will be used as a core organization
entity
Entity2: Available in a semantic model and contains data that meets organizational
standards
Entity3: Available in a Microsoft Power BI report and contains data that is ready for sharing
and reuse
Entity4: Available in a Power BI dashboard and contains approved data for executive-level
decision making
Your company requires that specific governance processes be implemented for the data.
You need to apply endorsement badges to the entities based on each entity’s use case.
Which badge should you apply to each entity? To answer, drag the appropriate badges the
correct entities. Each badge may be used once, more than once, or not at all. You may
need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
 |
Microsoft DP-700 Exam Dumps
5 out of 5
Pass Your Implementing Data Engineering Solutions Using Microsoft Fabric Exam in First Attempt With DP-700 Exam Dumps. Real Microsoft Fabric Data Engineer Associate Exam Questions As in Actual Exam!
— 66 Questions With Valid Answers
— Updation Date : 14-Apr-2025
— Free DP-700 Updates for 90 Days
— 98% Implementing Data Engineering Solutions Using Microsoft Fabric Exam Passing Rate
PDF Only Price 49.99$
19.99$
Buy PDF
Speciality
Additional Information
Testimonials
Related Exams
- Number 1 Microsoft Microsoft Fabric Data Engineer Associate study material online
- Regular DP-700 dumps updates for free.
- Implementing Data Engineering Solutions Using Microsoft Fabric Practice exam questions with their answers and explaination.
- Our commitment to your success continues through your exam with 24/7 support.
- Free DP-700 exam dumps updates for 90 days
- 97% more cost effective than traditional training
- Implementing Data Engineering Solutions Using Microsoft Fabric Practice test to boost your knowledge
- 100% correct Microsoft Fabric Data Engineer Associate questions answers compiled by senior IT professionals
Microsoft DP-700 Braindumps
Realbraindumps.com is providing Microsoft Fabric Data Engineer Associate DP-700 braindumps which are accurate and of high-quality verified by the team of experts. The Microsoft DP-700 dumps are comprised of Implementing Data Engineering Solutions Using Microsoft Fabric questions answers available in printable PDF files and online practice test formats. Our best recommended and an economical package is Microsoft Fabric Data Engineer Associate PDF file + test engine discount package along with 3 months free updates of DP-700 exam questions. We have compiled Microsoft Fabric Data Engineer Associate exam dumps question answers pdf file for you so that you can easily prepare for your exam. Our Microsoft braindumps will help you in exam. Obtaining valuable professional Microsoft Microsoft Fabric Data Engineer Associate certifications with DP-700 exam questions answers will always be beneficial to IT professionals by enhancing their knowledge and boosting their career.
Yes, really its not as tougher as before. Websites like Realbraindumps.com are playing a significant role to make this possible in this competitive world to pass exams with help of Microsoft Fabric Data Engineer Associate DP-700 dumps questions. We are here to encourage your ambition and helping you in all possible ways. Our excellent and incomparable Microsoft Implementing Data Engineering Solutions Using Microsoft Fabric exam questions answers study material will help you to get through your certification DP-700 exam braindumps in the first attempt.
Pass Exam With Microsoft Microsoft Fabric Data Engineer Associate Dumps. We at Realbraindumps are committed to provide you Implementing Data Engineering Solutions Using Microsoft Fabric braindumps questions answers online. We recommend you to prepare from our study material and boost your knowledge. You can also get discount on our Microsoft DP-700 dumps. Just talk with our support representatives and ask for special discount on Microsoft Fabric Data Engineer Associate exam braindumps. We have latest DP-700 exam dumps having all Microsoft Implementing Data Engineering Solutions Using Microsoft Fabric dumps questions written to the highest standards of technical accuracy and can be instantly downloaded and accessed by the candidates when once purchased. Practicing Online Microsoft Fabric Data Engineer Associate DP-700 braindumps will help you to get wholly prepared and familiar with the real exam condition. Free Microsoft Fabric Data Engineer Associate exam braindumps demos are available for your satisfaction before purchase order.
Send us mail if you want to check Microsoft DP-700 Implementing Data Engineering Solutions Using Microsoft Fabric DEMO before your purchase and our support team will send you in email.
If you don't find your dumps here then you can request what you need and we shall provide it to you.
Bulk Packages
$50
- Get 3 Exams PDF
- Get $33 Discount
- Mention Exam Codes in Payment Description.
Buy 3 Exams PDF
$70
- Get 5 Exams PDF
- Get $65 Discount
- Mention Exam Codes in Payment Description.
Buy 5 Exams PDF
$100
- Get 5 Exams PDF + Test Engine
- Get $105 Discount
- Mention Exam Codes in Payment Description.
Buy 5 Exams PDF + Engine
 Jessica Doe
Microsoft Fabric Data Engineer Associate
We are providing Microsoft DP-700 Braindumps with practice exam question answers. These will help you to prepare your Implementing Data Engineering Solutions Using Microsoft Fabric exam. Buy Microsoft Fabric Data Engineer Associate DP-700 dumps and boost your knowledge.
|
